Haiyi Mei
梅海艺
I'm a

👋 I’m a committed algorithm researcher and backend engineer with 4+ years of industry experience. Specializing in 3D synthetic data generation for computer vision tasks, I have contributed to 10 papers in top-tier conferences and journals.
I’m well-versed in the text-to-video generation pipeline, contributing to VAE training, dataset preparation, automated annotation, and video acquisition using crawler techniques.
Beyond research, I’m passionate about developing autonomous AI agents, leveraging my backend expertise and cutting-edge LLMs to create intelligent, scalable solutions.
I thrive on pushing the boundaries of AI systems and automation.
My expertise spans:
Languages and tools I’m working with:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
As a key member of the development team, I designed and led the implementation of the core agentic framework for this production-grade autonomous system.
I’m well-versed in the entire T2V pipeline and passionate about pushing the boundaries of innovation in this field.
I spearheaded the development of XRFeitoria 
I held a principal role in designing SynBody, a large-scale synthetic dataset with layered human models.
I’m proficient in crafting advanced technology demonstration videos.
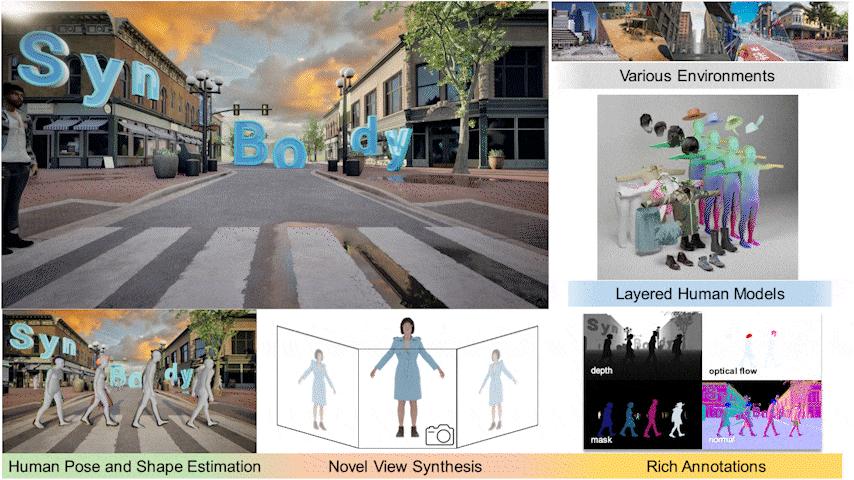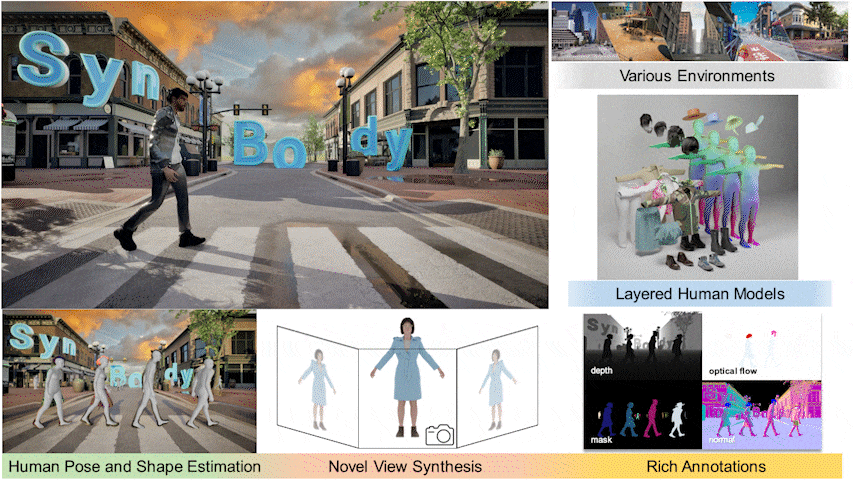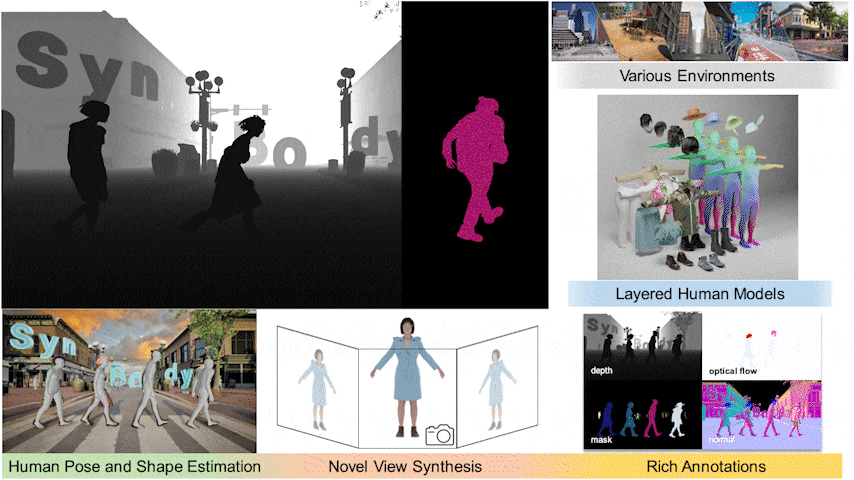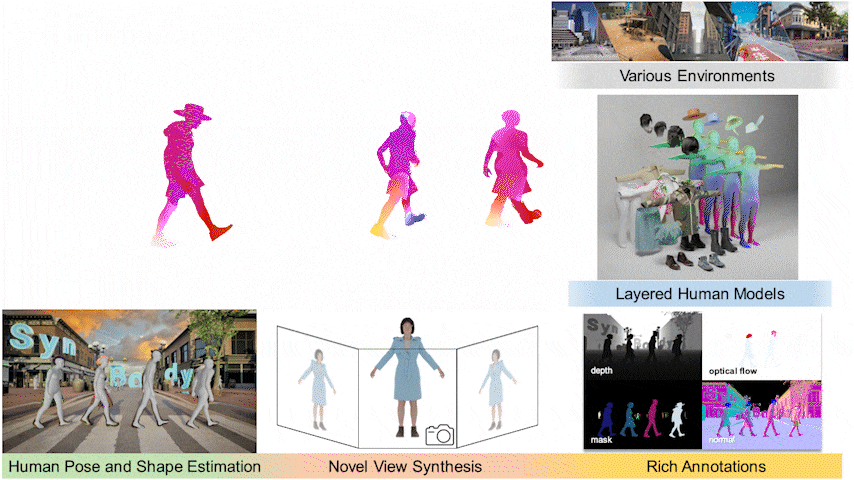



Started to work on synthetic data generation for computer vision tasks.
Had the experience of reproducing the SOTA methods in video captioning. Code




](/images/projects/digital-life-project.jpg)
](/images/projects/2024_cvpr_aios.gif)

](/images/projects/primdiffusion.gif)

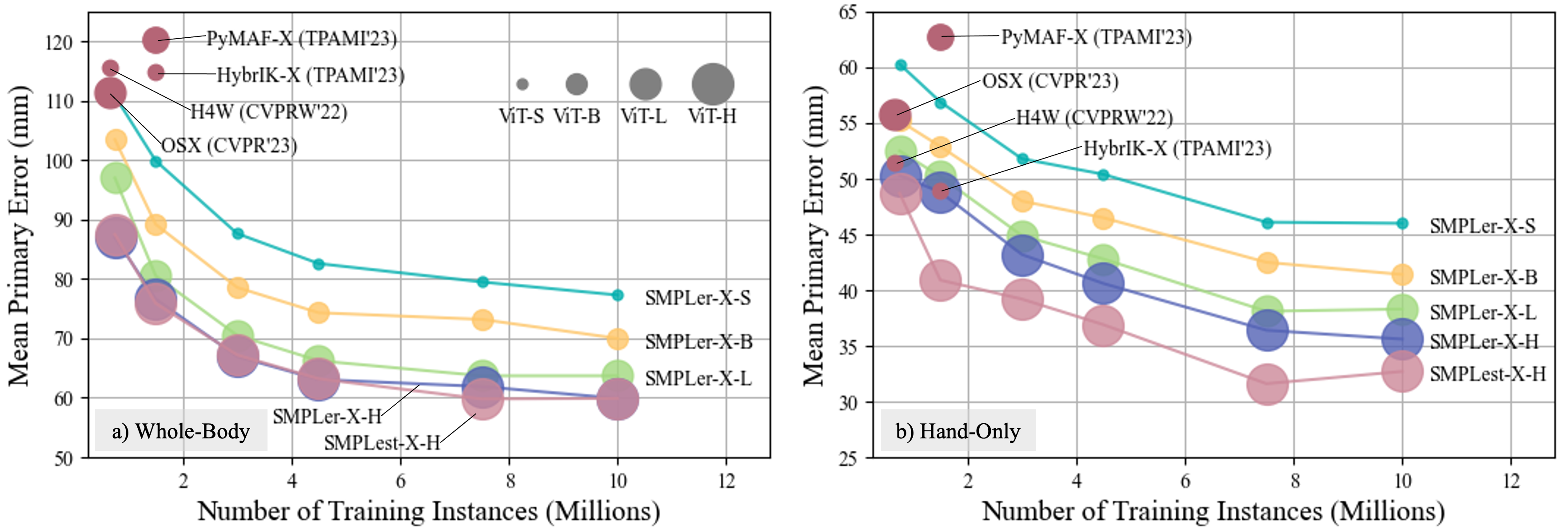
](/images/projects/smplerx.gif)

](/images/projects/zolly.jpg)

](/images/projects/SHERF.png)

](/images/projects/HumanLiff_thumbnail.gif)

I Published:
I Published:
Extracurricular Activities
🥳 Contact me for any questions or want to collaborate! Always open to new opportunities.
haiyimei [at] gmail.com